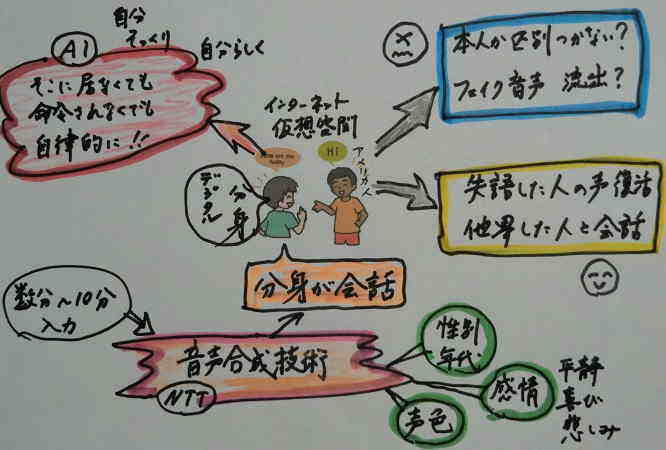
嘆丂俶俿俿偼惗惉恖岺抦擻乮俙俬乯傪妶梡偟丄偦偺恖偺惡傗榖偟曽傪杮暔偦偭偔傝偵帡偣偰嵞尰偡傞乽壒惡崌惉媄弍乿傪奐敪偟偨偲敪昞偟傑偟偨丅偙傟傑偱屄恖偺摿挜傪妛廗偟嵞尰偡傞偵偼戝検偺僨乕僞偑昁梫偱偟偨偑丄怴媄弍偼悢暘乣侾侽暘掱搙偺壒惡僨乕僞傪婡夿偵撉傒崬傑偣傟偽惡偺崌惉偑壜擻偲側傝傑偟偨丅傑偨丄惈暿傗擭戙偵傛傞惡怓偺摿挜傪崅偄儗儀儖偱嵞尰偡傞偩偗偱側偔丄摨偠尵梩偱傕乽暯惷乿乽婌傃乿乽斶偟傒乿側偳丄姶忣偵曄壔傪偮偗偰敪惡偱偒傞傛偆偵側傝傑偟偨丅
嘇丂媄弍偺幚墘偱偼丄抁偄夛榖偐傜崅楊幰偺惡壒傗榖偟曽偺摿挜傪偲傜偊丄杮恖偲暦偒娫堘偊傞傎偳偺崌惉壒惡偵惉岟偟傑偟偨丅NTT偺愢柧偵傛傞偲丄彨棃揑偵偼帺暘偺戙傢傝偵懠恖偲夛榖偡傞乽僨僕僞儖暘恎乿傪扤傕偑帩偰傞傛偆偵側傞偲偺偙偲偱偡丅傑偨丄幚嵺偵偼帺暘帺恎偑偦偙偵嶲壛偟偰偄側偔偰傕丄乮柦椷偝傟側偔偰傕乯帺棩揑偵妶摦偡傞暘恎偑乮僀儞僞乕僱僢僩偺乯壖憐嬻娫忋偱丄帺暘偺戙傢偭偰丄傑傞偱帺暘偺傛偆偵帺暘傜偟偔夛榖偟偰偔傟傞傛偆偵側傞偲偺偙偲偱偡丅
嘊丂偙傟偑壜擻偵側傞偲丄夛榖偟偰偄傞憡庤偼杮恖側偺偐俙俬壒惡側偺偐嬫暿偑晅偐側偐偭偨傝丄僼僃僀僋乮偵偣傕偺乯壒惡偑弌夞偭偨傝偡傞側偳丄備備偟偒乮尒夁偛偣側偄乯悽偺拞偵側傞壜擻惈偑偁傝傑偡丅偟偐偟丄偦偺堦曽偱昦婥側偳偱幐岅偟偨乮榖偣側偄乯恖偺惡傪暅妶偝偣偨傝丄懠奅偟偨恖乮朣偔側偭偨恖乯偲儕傾儖側夛榖偑偱偒偨傝偲偄偭偨妶梡偑尒崬傑傟偰偄傑偡丅